HashMap 概述
HashMap 是基于哈希表的 Map 接口的非同步实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap 的数据结构
在 java 编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap 也不例外。HashMap实际上是一个“ 链表散列”。
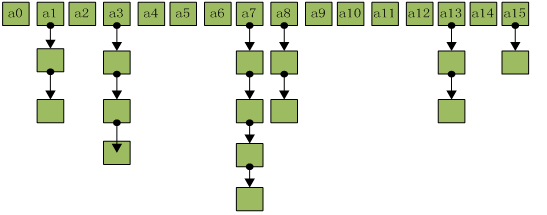
从上图中可以看出,HashMap 底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个 HashMap 的时候,就会初始化一个数组。
源码如下:
1 | /** |
可以看出,Entry 就是数组中的元素,每个 Map.Entry 其实就是一个 key-value 对,它持有一个指向下一个元素的引用,这就构成了链表。
HashMap 的存取实现
put方法
1 | public V put(K key, V value) { |
(1)当table为空时,就调用inflateTable方法扩大table的容量,inflateTable的源码如下,入参是要把table的扩大的容量大小,但由于table的容量只能是2的幂次方(原因稍后会解释),所以为了保证存储需求且最节省空间,需要先计算出大于等于且最接近2的幂次方,然后实例化table,数组容量为新计算出的长度capacity。
1 | private void inflateTable(int toSize) { |
(2)如下面putForNullKey()方法源码所示,当put的元素key值为null时,会把该元素存储到HashMap的数组下标为0的链表上,先遍历该链表,找到key是null的节点,用新的value替换旧的value;如果没有找到key是null的节点,就直接在数组下标为0的链表上添加该元素(键值对)。
1 | private V putForNullKey(V value) { |
(3)计算key的hash,根据hash计算数组下表
hash(key)方法是根据key值计算并返回一个整型的数,在Java7中,如果key为String,主要以sun.misc.Hashing.stringHash32((String) k)的方式计算,否则对hashSeed和key的hashCode进行异或运算,再进行无符号右移、异或计算,如下:
1 | final int hash(Object k) { |
在Java8中,直接(h = key.hashCode()) ^ (h >>> 16),如下:
1 | static final int hash(Object key) { |
计算出hash值后,需要根据hash值来计算数组的下标,如下代码:
1 | static int indexFor(int h, int length) { |
计算数组下标直接用hash值和数组长度-1进行与运算,因为计算出来的hash值是一个整型数据,范围在-2^31~2^31-1,大约有40多亿个数,怎么根据这40多亿中的一个数来决定数组的其中一个下标呢,为了便于理解来举个例子:
比如我们向HashMap中存入了两个键值对entry1(key1=”abc”,value1=”ABC”)、entry2(key2=”def”,value1=”DEF”),假设key1对应的hash值为18,二进制为10010,假设key2对应的hash值为27,二进制为11011。

其中会发现一个规律,如果数组长度为2的幂次方,那么数组长度-1的二进制每个位数的值都是1,与key的hash进行&运算之后的结果,除了超过数组长度-1数值的高位部分,低位部分都与key的hash值一致。
如果数组长度不是2的幂次方,比如15,结果会是什么样呢?如下图:

当数组长度是15的时候,其二进制末尾数值为0,计算结果的末尾肯定永远是0,所以永远不会有计算结果为00001、00011、00101、00111、01001、01011、01101、01111这几种末尾是1的情况,也就是数组下标为1、3、5、7、9、11、13、15这几个位置永远都不会存储数据,造成了严重的空间浪费,这就是HashMap中的数组长度必须是2的幂次方的原因。
(4)存储元素
找到数组下标之后,就要存储元素啦,有两种情况:1、put元素的key值已经存在;2、put元素的key值不存在。第一种情况会先遍历数组下标对应空间存储的链表,如果存在该key值的节点,就把对应新的value替换旧的value;第二种情况,需要调用addEntry(hash,key,value,数组下标)来新创建一个节点元素,创建节点元素之前,先进行扩容判断操作,如过需要扩容,就把数组空间扩大之后才创建新节点,addEntry()方法的源码如下:
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
size就是HashMap中目前存储元素的个数,threshold的值是扩容临界值(数组长度*加载因子),当size大于等于threshold并且数组当前位置存储内容不为空时,就调用resize方法进行扩容操作(java1.6之前只要size大于等于threshold就会扩容),扩大后的容量为数组长度的2倍。扩容的核心逻辑在resize方法调用的transfer方法中,主要就是把原来table中的元素复制到扩容后的newTable中:
1 | void transfer(Entry[] newTable, boolean rehash) { |
为了比较直观地理解transfer方法这段代码,画了几张图,假如HashMap中现在有entry1、entry2、entry3、entry4四个元素,且他们在table中的存储位置如下:

for循环遍历的是table数组中的每一个元素,while循环遍历的是每一条链表上的节点。当第一次执行完Entry next = e.next;后,e指向的是enty1,next指向的是entry2;当第一次执行完int i = indexFor(e.hash, newCapacity);后,i的值就是e(entry1)在新表中计算出来的下标(这里假设i=2);当第一次执行完e.next = newTable[i];后,entry1的next就指向newTable[2],也就是null(这一步是重点,会导致在同一条链中新节点总会插入到链表头);当第一次执行完newTable[i] = e;后,entry1已经被转移到了新表数组下标是2的链表中,如下图:

第二次while循环后的结果是entry2节点被转移到新表下标是7的链表中,如下图:

第三次while循环时,执行完 Entry next = e.next; 后,e指向的是enty3,next指向的是null;当执行完int i = indexFor(e.hash, newCapacity);后,i的值就是e(entry3)在新表中计算出来的下标(这里假设i=2);当执行完e.next = newTable[i];后,entry3的next就指向newTable[2],也就是entry1(这一步是重点,会导致在同一条链中新节点总会插入到链表头);当执行完newTable[i] = e;后,entry3已经插入到新表数组下标是2的链表头部,如下图;当执行完e = next;,e的值为null,结束本次while循环。

下图是第二次for循环执行后的结果,entry4插入到新表下标为2的链表头部:

get方法
1 | public V get(Object key) { |
从 HashMap 中 中 get 元素时,首先计算 key 的 hashCode ,找到数组中对过 应位置的某一元素,然后通过 key 的 的 equals 方法在对应位置的链表中找到需要的元素。
归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,个 当需要存储一个 Entry 对象时,会根据 hash 算法来决定其在数组中的存储位置,在根据equals 方法决定其在该数组位置上的链表中的存储位置;当需要取出一个 Entry 时,也会根据 hash 算法找到其在数组中的存储位置,再根据 equals 方法从该位置上的链表中取出该 Entry。
HashMap 的 的 resize
当 当 HashMap 中的元素越来越多的时候,hash 冲突的几率也就越来越高,因为数组的对长度是固定的。所以为了提高查询的效率,就要对 HashMap 的数组进行扩容,数组扩容在 这个操作也会出现在 ArrayList 中,这是一个常用的操作,而在 HashMap 数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,是 这就是 resize 。
那么 HashMap 什么时候进行扩容呢?当 HashMap 中的元素个数超过数组大小loadFactor 时,就会进行数组扩容,loadFactor 的默认值为 0.75 ,这是一个折中的取值。为 也就是说,默认情况下,数组大小为 16 ,那么当 HashMap 中元素个数超过 160.75=12的时候,就把数组的大小扩展为 216=32 ,即扩大一倍,然后重新计算个元素在数组中知 的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知 HashMap 中元素的个高 数,那么预设元素的个数能够有效的提高 HashMap 的性能。
HashMap 的性能参数
HashMap 包含如下几个构造器:
- HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
- HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
- HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
- HashMap 的基础构造器 HashMap(int initialCapacity, float loadFactor)带有两个参数,它们是初始容量 initialCapacity 和加载因子 loadFactor。
- initialCapacity:HashMap 的最大容量,即为底层数组的长度。
- loadFactor:负载因子 loadFactor 定义为:散列表的实际元素数目(n)/ 散列表的容量(m)。
- 负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是 O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
HashMap 的实现中,通过 threshold 字段来判断 HashMap 的最大容量:threshold = (int)(capacity * loadFactor);
结合负载因子的定义公式可知,threshold 就是在此 loadFactor 和 capacity 对应下允许的最大元素数目,超过这个数目就重新 resize,以降低实际的负载因子。默认的的负载因子0.75是对空间和时间效率的一个平衡选择。当容量超出此最大容量时, resize后的HashMap容量是容量的两倍:
1 | if (size++ >= threshold) |
Fail-Fast 机制
我们知道 java.util.HashMap 不是线程安全的,因此如果在使用迭代器的过程中有其了 他线程修改了 map ,那么将抛出 ConcurrentModificationException ,这就是所谓 fail-fast策略。
这一策略在源码中的实现是通过 modCount 域,modCount 顾名思义就是修改次数,对HashMap 内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。
1 | HashIterator() { |
在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 Map:注意到 modCount 声明为 volatile,保证线程之间修改的可见性。
1 | final Entry<K,V> nextEntry() { |
在 HashMap 的 API 中指出:
- 由所有 HashMap 类的“collection 视图方法”所返回的迭代器都是快速失败的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险。
- 注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
部分转载于DannyHoo